
📝 Introduction
I’ll share key insights from building a simple Guardrails model to classify toxic content. Guardrails play a crucial role in LLM-based applications by preventing models from generating harmful or undesirable content.
Recently, there has been significant research on leveraging large language models (LLMs) themselves to critique, judge, and classify harmful content using techniques like instruction-following (IF) and in-context learning (ICL). For example, the framework “Self-Criticism” proposed by Tan, X. et. al., 2023 allows LLMs to self-align to helpful, honest, and harmless (HHH) standards based on what they leant from extensive text corpus during training.
Another example is Meta’s Llama Guard, a Llama2-7B model developed by Inan et al., 2023, which has been fine-tuned specifically for content safety classification.
In both approaches, LLMs are central to determining what qualifies as toxic content. However, this approach presents a reliability challenge – LLMs are not deterministic, meaning they can produce different outputs for the same input, which may impact consistency.
🤔 This made me wonder: Do LLM-based toxic content classifiers truly outperform neural network classifiers in accuracy?
The results were surprising!
Background
This section provides an overview of Guardrails, their purpose, and current implementations.
What are Guardrails?
Guardrails are filtering mechanisms in LLM-based applications that safeguard against generating toxic, harmful, or otherwise undesired content. They act as essential tools to mitigate risks associated with LLM use, such as ethical concerns, data biases, privacy issues, and overall robustness.
As LLMs become more widespread, the potential for misuse has grown, with risks ranging from spreading misinformation to facilitating criminal activities Goldstein et al., 2023.
In simple terms, a guardrail is an algorithm that reviews the inputs and outputs of LLMs and determines whether they meet safety standards.
For example, if a user’s input contains hate speech, a guardrail could either prevent the input from being processed by the LLM or adapt the output to ensure it remains harmless. In this way, Guardrails intercept potentially harmful queries and help prevent models from responding inappropriately.
Depending on the application, Guardrails can be customized to block various types of content, including offensive language, hate speech, hallucinations, or areas of high uncertainty. They also help ensure compliance with ethical guidelines and specific policies, such as fairness, privacy, or copyright protections Dong, Y. et al. 2024.
Examples of Open-Source Guardrail Frameworks
1. Llama Guard (Inan et al., 2023)
Llama Guard is a fine-tuned model that takes both input and output from an LLM and categorizes them based on user-specified criteria. While useful, its reliability can vary, as classification depends on the LLM’s understanding of the categories and predictive accuracy.
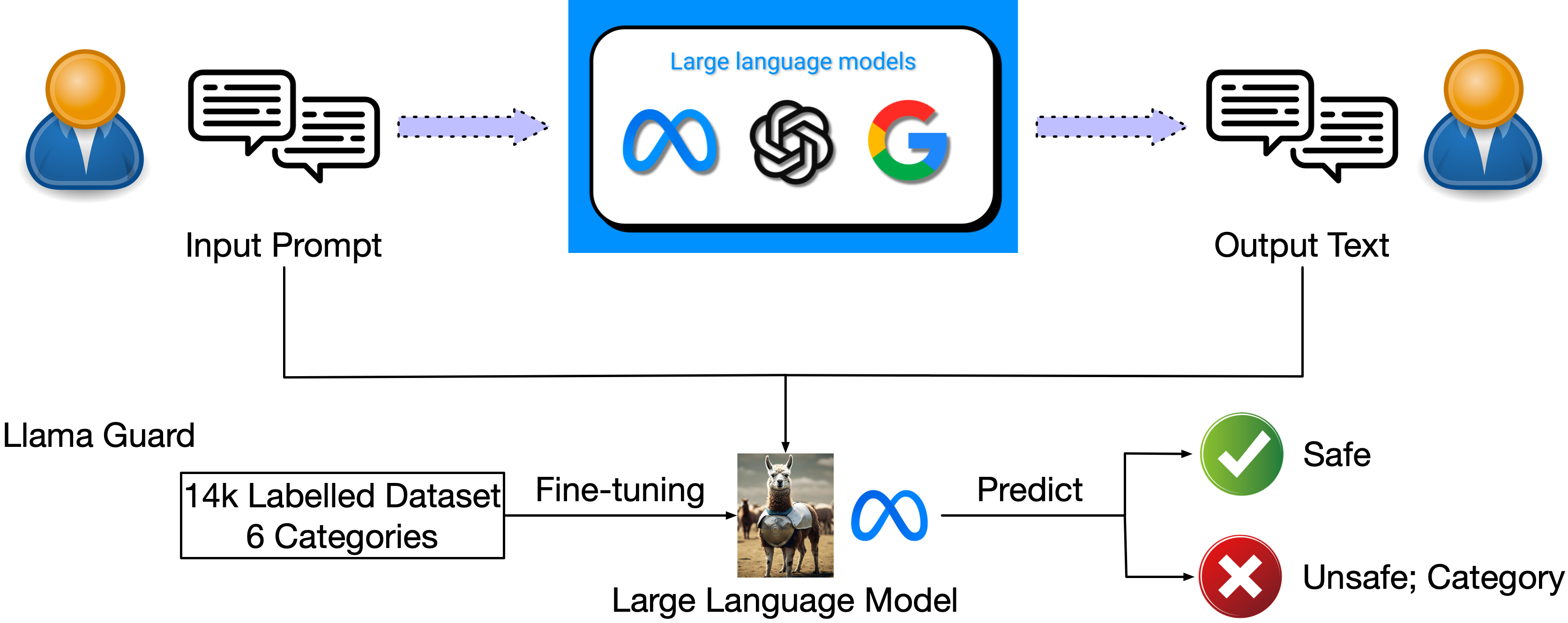
Llama Guard Framework overview (Dong, Y. et al. 2024)
2. Nvidia NeMo (Rebedea et al., 2023)
NeMo serves as an intermediary layer to enhance control and safety in LLM applications. When a customer’s prompt is received, NeMo converts it into an embedding vector, then applies a K-nearest neighbors (KNN) approach to match it with stored vectors representing standard user inputs (canonical forms). This retrieves the embeddings most similar to the prompt, which NeMo uses to guide output generation from the corresponding canonical form. Throughout this process, NeMo can use the LLM to produce safe responses as specified by the Colang program. Additionally, NeMo includes pre-built moderation tools, such as fact-checking, hallucination prevention, and content moderation, to further safeguard outputs.
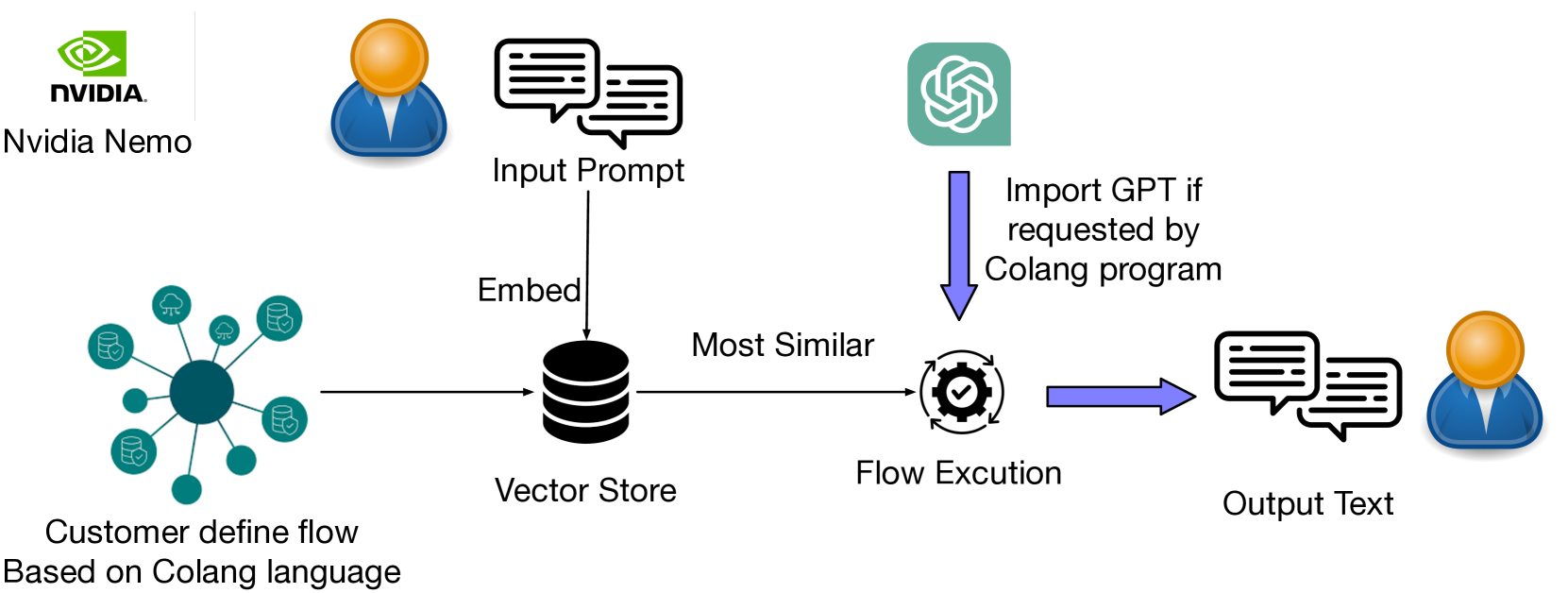
Nvidia Nemo Guardrails Framework (Dong, Y. et al. 2024)
Objective
The goal of this work was to examine whether LLM-based toxic content classifiers genuinely surpass neural network classifiers in terms of accuracy.
Methodology
I evaluated the performance of two binary classifiers:
- Llama3 8B with in-context-learning (ICL)
- Two Layer Neural Network - a feed-forward neural network that I trained on the Wikipedia Toxic Comments training dataset.
Dataset
For this experiment, I used the Wikipedia Toxic Comments dataset, which includes toxic comments and hate speech from Wikipedia, with each comment labeled by humans as either 1 (“toxic”) or 0 (“safe”).
To support training, validation, and testing, I divided the dataset into three balanced subsets that contains equal number of samples for each category 0 or 1:
- Training Dataset - 25,868 samples
- Validation Dataset - 6,582 samples
- Test Dataset - 3,000 samples
The Training and Validation datasets were used to train a neural network classifier.
For evaluating the performance of the classifiers, I used the Test dataset.
Classifiers
For the experiment, I set up two different classifiers:
Llama3 8B with ICL
I used Meta’s Llama3 model to classify toxic content using the Test Dataset. Using in-context-learning the LLM is tasked to classify user comment as toxic or safe by returning 0 for “safe” or 1 for “toxic” content. If the LLM can not return the answer or does not know, it should return 2. I used a similar prompt structure and toxic content categories as per Inan et al., 2023 paper. Below is an example of such a prompt:
"""
Task: Check if there is toxic content in 'User' comment according to our toxic content categories below.
<BEGIN TOXIC CONTENT CATEGORIES>
Violence and Hate
Sexual Content
Guns & Illegal Weapons
Regulated or Controlled Substances
Suicide and Self Harm
Criminal Planning
<END TOXIC CONTENT CATEGORIES>
<BEGIN USER COMMENT>
{USER_COMMENT}
<END USER COMMENT>
Provide your safety assesment for the above user comment.
Only provide a single number:
1 if user comment is "Toxic" or
0 if user comment is "Safe"
Do not provide explanation or justification. If you can not provide the answer output number 2. You are not allowed to output non numeric answer. You can only output 0, 1 or 2."""
Feed-forward Neural Network
I train a simple 2 layer neural network with the following architecture:
- Input layer: 1024
- Hidden layer 1: 100
- Hidden layer 2 (with dropout): 25
- Output: 2
The below code shows the neural network architecture:
class NeuralNet(nn.Module):
"""
Feed forward Neural Network architecture
"""
def __init__(self, input_size, hidden1, hidden2, output_size):
super(NeuralNet, self).__init__()
self.input_size = input_size
self.hidden1 = hidden1
self.hidden2 = hidden2
self.output_size = output_size
self.i2h = nn.Linear(self.input_size, self.hidden1)
self.h2h = nn.Linear(self.hidden1, self.hidden2)
self.h2o = nn.Linear(self.hidden2, self.output_size)
self.dropout = nn.Dropout(p=0.2)
def forward(self, x):
x = F.relu(self.i2h(x))
x = F.relu(self.dropout(self.h2h(x)))
x = self.h2o(x)
return x
For each data sample, I generated embeddings using the mGTE sentence embedding model developed by Alibaba Group, which is accessible here.
I use Cross Entropy Loss and Stochastic Gradient Descent optimizaton.
The below figure shows the training and validation loss for each epoch during training.
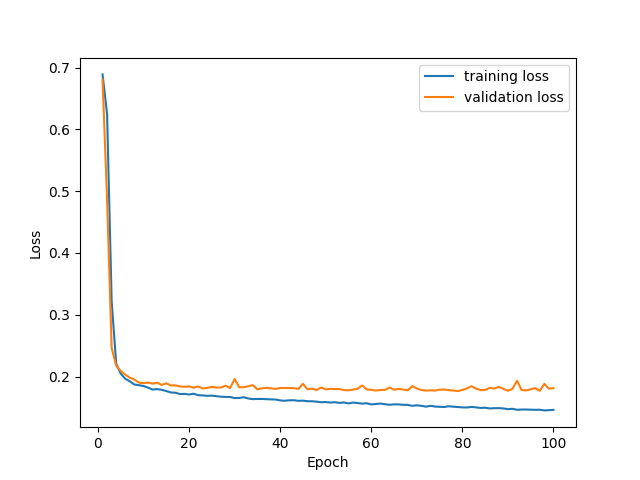
Training and validation loss during Neural Network training
After the training, the performance of the neural network was evaluated on the Test Dataset.
Results
Here is the most interesting part.

The neural network model significantly outperformed the LLM-based classifier across all evaluation metrics. The LLM failed to classify 146 samples. I updated their labels to 1 assuming that we want a model with high recall score.
See the results in the table below:
| Metric | Llama3 7B with ICL | Neural Network |
|---|---|---|
| Accuracy | 0.8 | 0.9 |
| Precision | 0.82 | 0.86 |
| Recall | 0.78 | 0.96 |
| F1 Score | 0.8 | 0.91 |
Below, are confusion matrices for both classifiers:
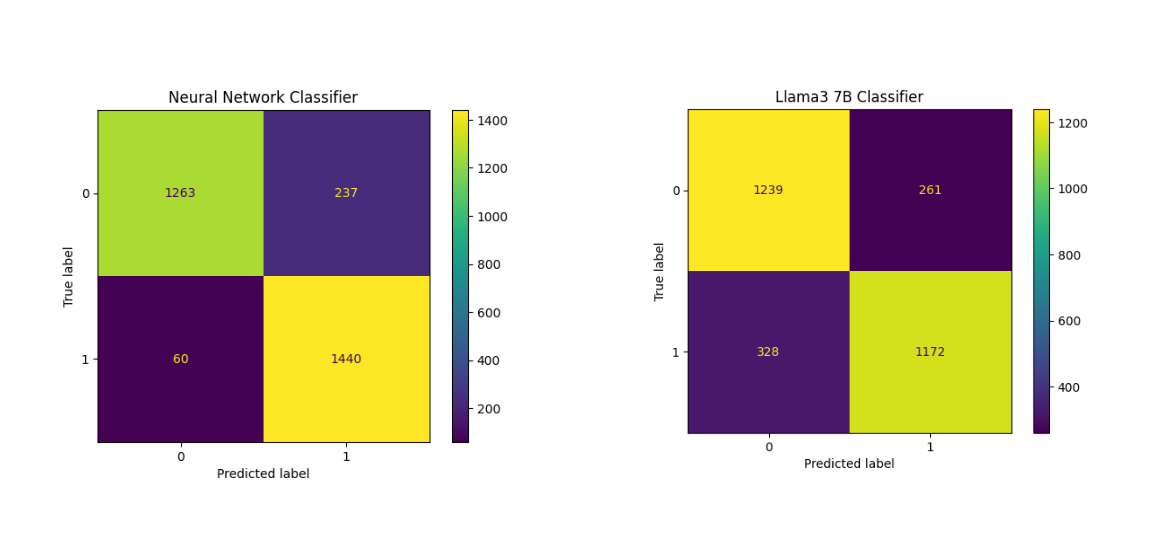
Confusion matrices
For a toxic content classification system, achieving a high recall rate is essential to ensure maximum detection of harmful content. High recall minimizes the risk of leaving harmful content undetected. For toxic content moderation, undetected content is a higher risk to user safety than occasional false positives (content wrongly flagged as toxic but isn’t harmful). Consequently, the neural network with a recall rate of 0.96 would be preferable to the LLM-based classifier, which achieved a recall rate of only 0.78.
Limitations and next steps
To implement the Llama3.1 8B model, I utilized the Ollama framework, a streamlined tool for running LLMs on local machines. Due to quantization, model performance may have been significantly affected. As a next step, I plan to conduct the same experiment with the full Llama3.1 model on AWS Bedrock. Additionally, I plan to test the Llama Guard model under similar conditions.
For further refinement, the neural network could be trained on a broader range of toxic content types, and alternative architectures and embedding models could be explored.
In addition, I tried to run the same experiment with OpenAI’s GPT-3.5 API but after approximately 200 requests, the API returned an error citing “repetitive patterns in the prompt.”
Another important factor to consider is the efficiency of running the Guardrails model in a production environment. On average, generating a single classification result takes approximately 2-3 seconds with both models. For the neural network model, the majority of this time 2-3 seconds is spent generating input embeddings, while the actual classification process itself takes only a few milliseconds.
An additional 2-3 second delay could negatively impact the overall end-user experience. Therefore, the next step is to address the runtime issue by exploring distillation methods for the embedding model used alongside the neural network classifier.
Conclusion
The objective of this experiment was to assess whether LLM-based toxic content classifiers offer advantages in accuracy over other machine learning models, such as neural networks.
This study compared the performance of a large language model (Llama3 8B with in-context learning) and a two layer neural network classifier for detecting toxic content. Results indicate that the feed-forward neural network significantly outperformed the LLM-based classifier across key metrics, achieving an accuracy score of 0.9 and a recall rate of 0.96, while the LLM-based classifier achieved an accuracy of 0.8 and a recall of 0.78. These findings highlight that for tasks requiring high recall in content moderation, neural network classifiers may provide superior performance with a reduced computational burden.
Future work will involve testing a non-quantized version of Llama3.1 on AWS Bedrock to assess any improvements in performance. Additionally, exploring the Llama Guard model and experimenting with more diverse training data and alternative architectures will help refine the neural network classifier further.
While this experiment focused primarily on enhancing recall, the next objective will be to improve model efficiency. Specifically, I will explore distillation techniques for sentence embedding model to develop a more efficient student model suitable to run in a production environment.
🔗 Code
Full code can be found here